最近挨踢小茶通过了我的第三门AWS的考试Certified SysOps Administrator – Associate,这也是我最后一门Associate级别的考试。下面我将考试所使用的笔记分享给大家,也方便自己日后查看。
SysOps Administrator – Associate的考试内容其实和另外两门有很大的重叠,因此可以先看一看AWS Certified Solutions Architect – Associate考试笔记。而作为一个针对系统管理员/运维者的考试,SysOps的考试将更多的重心放在了CloudWatch, ELB, AutoScaling, Billing, Security, RDS Read Replica, Elastic Cache等等内容。
- Amazon EC2 Metrics and Dimensions
- Monitoring Memory and Disk Metrics for Amazon EC2 Linux Instances
- Monitoring the Status of Your Volumes
- Which Metrics Should I Monitor?
- Instance Types
- Classic Load Balancer FAQs
- Application Load Balancer FAQs
- Amazon EC2 FAQs
- Auto Scaling FAQs
- Amazon CloudWatch FAQs
CloudWatch
Host level metrics consist of:
- CPU
- Network
- Disk
- Status Check
RAM Utilization is a custom metric
Detail monitoring
- By default EC2 monitoring is 5 minute intervals, unless you enable detailed monitoring which will then make it 1 minute intervals. And it will make additional cost.
- CloudWatch provides detailed monitoring of Elastic Load Balancing by default. Unlike Amazon EC2, you do not need to specifically enable detailed monitoring. And it will NOT make additional cost.
- Services, such as RDS, ELB, OpsWorks and Route 53 can provide the monitoring data every minute without charging the user.
Custom Metric
AWS CloudWatch supports the custom metrics. The user can always capture the custom data and upload the data to CloudWatch using CLI or APIs. The user has to always include the namespace as a part of the request. However, the other parameters are optional. If the user has uploaded data using CLI, he can view it as a graph inside the console. The data will take around 2 minutes to upload but can be viewed only after around 15 minutes.
Monitoring EBS
- You can burst performance to 3000 IOPS if you want
- Pre-warming EBS volumes, For a new volume created from a snapshot, you should read all the blocks that have data before using the volume.
- Status is Warning = Degraded or Severely Degraded
- Status is Impared = Stalled or Not Available
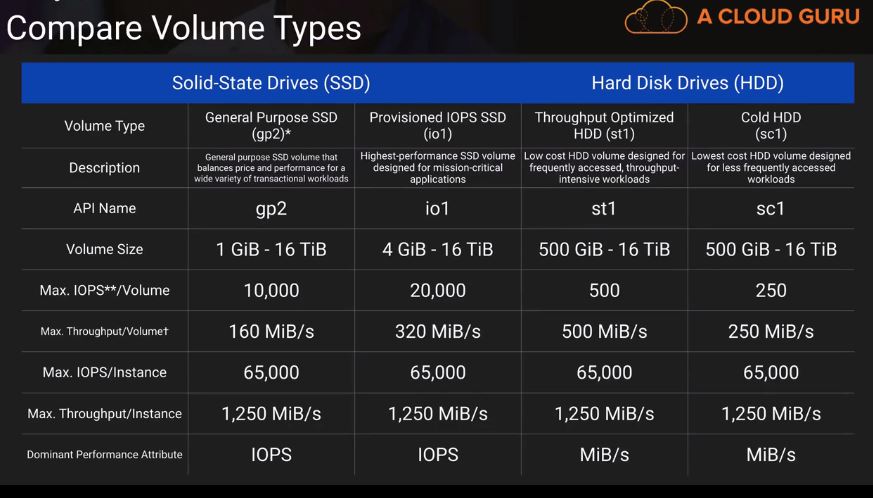
- Amazon Elastic Block Store (Amazon EBS) sends data points to CloudWatch for several metrics. Amazon EBS General Purpose SSD (gp2), Throughput Optimized HDD (st1), Cold HDD (sc1), and Magnetic (standard) volumes automatically send five-minute metrics to CloudWatch. Provisioned IOPS SSD (io1) volumes automatically send one-minute metrics to CloudWatch.
- For an EC2 instance launched with an EBS backed AMI, each time the instance state is changed from stop to start/ running, AWS charges a full instance hour, even if these transitions happen multiple times within a single hour. Anyway, rebooting an instance AWS does not charge a new instance billing hour.
Monitoring RDS
Some metrics - DatabaseConnections, DiskQueueDepth, FreeStorageSpace, ReplicaLag(Seconds), ReadIOPS, WriteIOPS, ReadLatency, WriteLatency
Monitoring ELB
Metric SurgeQueueLength - a count of the total number of requests that are pending submission to a registered instance
Metric SpilloverCount - a count of total number of request that were rejected due to the queue being full
Monitoring Elasticache
CPU Utilization
- Memcached
- Multi-threaded
- Can handle loads of up to 90%
- Redis
- Not multi-threaded
- If you are using 4 cores, the threshold of CPU UTL is 90/4 = 22.5%
Swap Usage
- Memcached
- Should be around 0 most of the time
- If it exceeds 50Mb you should increase memcached_connections_overhead parameter
- Redis
- No SwapUsage metric
Evictions
- Memcached
- Either scale up (increase memory)
- or scale out (add more nodes)
- Redis
- Only scale out (add read replicas)
Concurrent Connections
- No recommended settings, choose a threshold based off application
AWS Organizations
- Consolidated Billing, allows you to get volume discounts on all your accounts
- 20 linked accounts only, contact AWS if you need more
- Unused reserved instances for EC2 are applied across the group
- CloudTrail is on a per account and per region basis but can be aggregated in to a single bucket in the paying account
High Availability
Read Replica
- Supported versions of Mysql is 5.6 (Not 5.1 or 5.5), with InnoBD engines
- Supported versions of PostgreSQL is 9.3.5 or newer
- Creating Read Replica if multi-AZ is NOT enabled: snapshot will be of your primary DB and can cause 1 minute I/O suspension
- Creating Read Replica if multi-AZ is enabled: snapshot will be of your secondary DB and you will not experience any performance hits on you primary DB
- You can promote a read repliaca to it's own standalone DB
- You can have up to 5 read replicas for both MYSQL and PostgreSQL
- You can have read replicas in different regions but for MYSQL only
- Replication is Asynchronous only, not synchronous
- DB Snapshots and Automated backups cannot be taken of read replicas
- Key Metric to look for is REPLICA LAG
- Automated Backup needs to be enalbed if you want to create Read Replica
- Cannot have multi-AZ settings for Read Replica
Services with root/admin access to OS
- Elastic Beanstalk
- Elastic MapReduce
- OpsWork
- EC2
ELB
- Duration-based session stickiness
- application-controlled session stickiness
ELB Log File format
- bucket[/prefix]/AWSLogs/aws-account-id/elasticloadbalancing/region/yyyy/mm/dd/aws-account-id_elasticloadbalancing_region_load-balancer-name_end-time_ip-address_random-string.log
Configure Sticky Sessions for Your Classic Load Balancer - By default, a Classic Load Balancer routes each request independently to the registered instance with the smallest load. However, you can use the sticky session feature (also known as session affinity), which enables the load balancer to bind a user's session to a specific instance. This ensures that all requests from the user during the session are sent to the same instance.
http://docs.aws.amazon.com/elasticloadbalancing/latest/classic/elb-sticky-sessions.html
Connection Draining - The Elastic Load Balancer connection draining feature causes the load balancer to stop sending new requests to the back-end instances when the instances are deregistering or become unhealthy, while ensuring that inflight requests continue to be served. The user can specify a maximum time (3600 seconds. for the load balancer to keep the connections alive before reporting the instance as deregistered. If the user does not specify the maximum timeout period, by default, the load balancer will close the connections to the deregistering instance after 300 seconds.
RTO vs RPO
Recovery time objective (RTO)— The time it takes after a disruption to restore a business process to its service level, as defined by the operational level agreement (OLA). For example, if a disaster occurs at 12:00 PM (noon) and the RTO is eight hours, the DR process should restore the business process to the acceptable service level by 8:00 PM.
Recovery point objective (RPO) — The acceptable amount of data loss measured in time. For example, if a disaster occurs at 12:00 PM (noon) and the RPO is one hour, the system should recover all data that was in the system before 11:00 AM. Data loss will span only one hour, between 11:00 AM and 12:00 PM (noon).
Diaster Recovery
Pilot Light - The term pilot light is often used to describe a DR scenario in which a minimal version of an environment is always running in the cloud. The idea of the pilot light is an analogy that comes from the gas heater. In a gas heater, a small flame that’s always on can quickly ignite the entire furnace to heat up a house. This scenario is similar to a backup-and-restore scenario. For example, with AWS you can maintain a pilot light by configuring and running the most critical core elements of your system in AWS. When the time comes for recovery, you can rapidly provision a full-scale production environment around the critical core
Warm Standby - The term warm standby is used to describe a DR scenario in which a scaled-down version of a fully functional environment is always running in the cloud. A warm standby solution extends the pilot light elements and preparation. It further decreases the recovery time because some services are always running. By identifying your business-critical systems, you can fully duplicate these systems on AWS and have them always on.
Multi-site - A multi-site solution runs in AWS as well as on your existing on-site infrastructure,in an active-active configuration. The data replication method that you employ will be determined by the recovery pointthat you choose.
EBS vs Instance Store

EBS
- EBS volumes can be changed on the fly (except for magnetic standard)
- Best practice to stop the EC2 instance and then change the volume
- You can change volume types by taking a snapshot and then using the snapshot to create a new volume
- If you change a volume on the fly you must wait for 6 hours before making another change
- You can scale EBS volumes up only
- Volumes must be in the same AZ as the EC2 instance
Security Token Service (STS)
- Federation (typically AD)
- Federation with Mobile Apps (Use Facebook/Amazon/Google)
- Cross Account Access
Exam Tips:
- Develop an Identity Broker to communicate with LDAP and AWS STS
- Identity Broker always authenticates with LDAP first, Then with AWS STS
- Application then gets temporary access to AWS resources
S3 Permission Control
S3 ACL: The user can use ACLs to grant basic read/write permissions to other AWS accounts.
S3 Bucket Policy: The policy is used to grant other AWS accounts or IAM users permissions for the bucket and
the objects in it.
User Access Policy: Define an IAM user and assign him the IAM policy which grants him access to S3.


文章评论
欢迎各位留言交流。